Redis是什么? 日常运维 Redis 需要注意什么 ? 怎么降低Redis 内存使用 节省内存?
你的项目或许已经使用 Redis 很长时间了,但在使用过程中,你可能还会或多或少地遇到以下问题:
- 我的 Redis 内存为什么增长这么快?
- 为什么我的 Redis 操作延迟变大了?
- 如何降低 Redis 故障发生的频率?
- 日常运维 Redis 需要注意什么?
- 部署 Redis 时,如何做好资源规划?
- Redis 监控重点要关注哪些指标?
尤其是当你的项目越来越依赖 Redis 时,这些问题就变得尤为重要。
此时,你迫切需要一份「最佳实践指南」。
这篇文章,我将从以下七个维度,带你「全面」分析 Redis 的最佳实践优化:
- 内存
- 性能
- 高可靠
- 日常运维
- 资源规划
- 监控
- 安全
在文章的最后,我还会给你一个完整的最佳实践清单,不管你是业务开发人员,还是 DBA 运维人员,这个清单将会帮助你更加「优雅」地用好 Redis。
这篇文章干货很多,希望你可以耐心读完。

01
如何使用 Redis 更节省内存?
首先,我们来看一下 Redis 内存方面的优化。
众所周知,Redis 的性能之所以如此之高,原因就在于它的数据都存储在「内存」中,所以访问 Redis 中的数据速度极快。
但从资源利用率层面来说,机器的内存资源相比于磁盘,还是比较昂贵的。
当你的业务应用在 Redis 中存储数据很少时,你可能并不太关心内存资源的使用情况。但随着业务的发展,你的业务存储在 Redis 中的数据就会越来越多。
如果没有提前制定好内存优化策略,那么等业务开始增长时,Redis 占用的内存也会开始膨胀。
所以,提前制定合理的内存优化策略,对于资源利用率的提升是很有必要的。
那在使用 Redis 时,怎样做才能更节省内存呢?这里我给你总结了 6 点建议,我们依次来看:
1) 控制 key 的长度
最简单直接的内存优化,就是控制 key 的长度。
在开发业务时,你需要提前预估整个 Redis 中写入 key 的数量,如果 key 数量达到了百万级别,那么,过长的 key 名也会占用过多的内存空间。
所以,你需要保证 key 在简单、清晰的前提下,尽可能把 key 定义得短一些。
例如,原有的 key 为 user:book:123,则可以优化为 u:bk:123。
这样一来,你的 Redis 就可以节省大量的内存,这个方案对内存的优化非常直接和高效。
2) 避免存储 bigkey
除了控制 key 的长度之外,你同样需要关注 value 的大小,如果大量存储 bigkey,也会导致 Redis 内存增长过快。
除此之外,客户端在读写 bigkey 时,还有产生性能问题(下文会具体详述)。
所以,你要避免在 Redis 中存储 bigkey,我给你的建议是:
- String:大小控制在 10KB 以下
- List/Hash/Set/ZSet:元素数量控制在 1 万以下
3) 选择合适的数据类型
Redis 提供了丰富的数据类型,这些数据类型在实现上,也对内存使用做了优化。具体来说就是,一种数据类型对应多种数据结构来实现:

例如,String、Set 在存储 int 数据时,会采用整数编码存储。Hash、ZSet 在元素数量比较少时(可配置),会采用压缩列表(ziplist)存储,在存储比较多的数据时,才会转换为哈希表和跳表。
作者这么设计的原因,就是为了进一步节约内存资源。
那么你在存储数据时,就可以利用这些特性来优化 Redis 的内存。这里我给你的建议如下:
- String、Set:尽可能存储 int 类型数据
- Hash、ZSet:存储的元素数量控制在转换阈值之下,以压缩列表存储,节约内存
4) 把 Redis 当作缓存使用
Redis 数据存储在内存中,这也意味着其资源是有限的。你在使用 Redis 时,要把它当做缓存来使用,而不是数据库。
所以,你的应用写入到 Redis 中的数据,尽可能地都设置「过期时间」。
业务应用在 Redis 中查不到数据时,再从后端数据库中加载到 Redis 中。
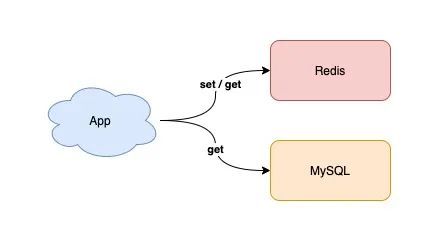
采用这种方案,可以让 Redis 中只保留经常访问的「热数据」,内存利用率也会比较高。
5) 实例设置 maxmemory + 淘汰策略
虽然你的 Redis key 都设置了过期时间,但如果你的业务应用写入量很大,并且过期时间设置得比较久,那么短期间内 Redis 的内存依旧会快速增长。
如果不控制 Redis 的内存上限,也会导致使用过多的内存资源。
对于这种场景,你需要提前预估业务数据量,然后给这个实例设置 maxmemory 控制实例的内存上限,这样可以避免 Redis 的内存持续膨胀。
配置了 maxmemory,此时你还要设置数据淘汰策略,而淘汰策略如何选择,你需要结合你的业务特点来决定:
- volatile-lru / allkeys-lru:优先保留最近访问过的数据
- volatile-lfu / allkeys-lfu:优先保留访问次数最频繁的数据(4.0+版本支持)
- volatile-ttl :优先淘汰即将过期的数据
- volatile-random / allkeys-random:随机淘汰数据
6) 数据压缩后写入 Redis
以上方案基本涵盖了 Redis 内存优化的各个方面。
如果你还想进一步优化 Redis 内存,你还可以在业务应用中先将数据压缩,再写入到 Redis 中(例如采用 snappy、gzip 等压缩算法)。
当然,压缩存储的数据,客户端在读取时还需要解压缩,在这期间会消耗更多 CPU 资源,你需要根据实际情况进行权衡。
以上就是「节省内存资源」方面的实践优化,是不是都比较简单?
下面我们来看「性能」方面的优化。
02
如何持续发挥 Redis 的高性能?
当你的系统决定引入 Redis 时,想必看中它最关键的一点就是:性能。
我们知道,一个单机版 Redis 就可以达到 10W QPS,这么高的性能,也意味着如果在使用过程中发生延迟情况,就会与我们的预期不符。
所以,在使用 Redis 时,如何持续发挥它的高性能,避免操作延迟的情况发生,也是我们的关注焦点。
在这方面,我给你总结了 13 条建议:
1) 避免存储 bigkey
存储 bigkey 除了前面讲到的使用过多内存之外,对 Redis 性能也会有很大影响。
由于 Redis 处理请求是单线程的,当你的应用在写入一个 bigkey 时,更多时间将消耗在「内存分配」上,这时操作延迟就会增加。同样地,删除一个 bigkey 在「释放内存」时,也会发生耗时。
而且,当你在读取这个 bigkey 时,也会在「网络数据传输」上花费更多时间,此时后面待执行的请求就会发生排队,Redis 性能下降。

所以,你的业务应用尽量不要存储 bigkey,避免操作延迟发生。
如果你确实有存储 bigkey 的需求,你可以把 bigkey 拆分为多个小 key 存储。
2) 开启 lazy-free 机制
如果你无法避免存储 bigkey,那么我建议你开启 Redis 的 lazy-free 机制。(4.0+版本支持)
当开启这个机制后,Redis 在删除一个 bigkey 时,释放内存的耗时操作,将会放到后台线程中去执行,这样可以在最大程度上,避免对主线程的影响。

3) 不使用复杂度过高的命令
Redis 是单线程模型处理请求,除了操作 bigkey 会导致后面请求发生排队之外,在执行复杂度过高的命令时,也会发生这种情况。
因为执行复杂度过高的命令,会消耗更多的 CPU 资源,主线程中的其它请求只能等待,这时也会发生排队延迟。
所以,你需要避免执行例如 SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
对于这种聚合类操作,我建议你把它放到客户端来执行,不要让 Redis 承担太多的计算工作。
4) 执行 O(N) 命令时,关注 N 的大小
规避使用复杂度过高的命令,就可以高枕无忧了么?
答案是否定的。
当你在执行 O(N) 命令时,同样需要注意 N 的大小。
如果一次性查询过多的数据,也会在网络传输过程中耗时过长,操作延迟变大。
所以,对于容器类型(List/Hash/Set/ZSet),在元素数量未知的情况下,一定不要无脑执行 LRANGE key 0 -1 / HGETALL / SMEMBERS / ZRANGE key 0 -1。
在查询数据时,你要遵循以下原则:
- 先查询数据元素的数量(LLEN/HLEN/SCARD/ZCARD)
- 元素数量较少,可一次性查询全量数据
- 元素数量非常多,分批查询数据(LRANGE/HASCAN/SSCAN/ZSCAN)
5) 关注 DEL 时间复杂度
你没看错,在删除一个 key 时,如果姿势不对,也有可能影响到 Redis 性能。
删除一个 key,我们通常使用的是 DEL 命令,回想一下,你觉得 DEL 的时间复杂度是多少?
O(1) ?其实不一定。
当你删除的是一个 String 类型 key 时,时间复杂度确实是 O(1)。
但当你要删除的 key 是 List/Hash/Set/ZSet 类型,它的复杂度其实为 O(N),N 代表元素个数。
也就是说,删除一个 key,其元素数量越多,执行 DEL 也就越慢!
原因在于,删除大量元素时,需要依次回收每个元素的内存,元素越多,花费的时间也就越久!
而且,这个过程默认是在主线程中执行的,这势必会阻塞主线程,产生性能问题。
那删除这种元素比较多的 key,如何处理呢?
我给你的建议是,分批删除:
- List类型:执行多次 LPOP/RPOP,直到所有元素都删除完成
- Hash/Set/ZSet类型:先执行 HSCAN/SSCAN/SCAN 查询元素,再执行 HDEL/SREM/ZREM 依次删除每个元素
没想到吧?一个小小的删除操作,稍微不小心,也有可能引发性能问题,你在操作时需要格外注意。
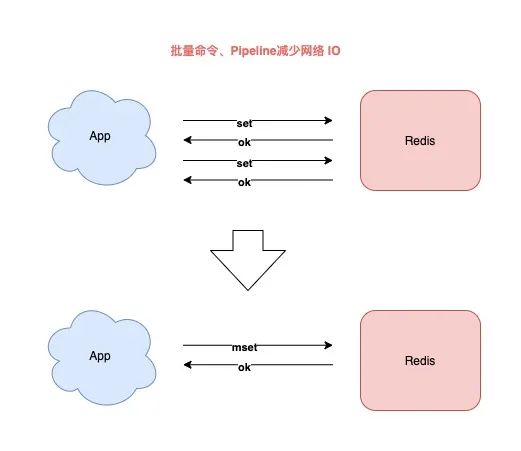
6) 批量命令代替单个命令
当你需要一次性操作多个 key 时,你应该使用批量命令来处理。
批量操作相比于多次单个操作的优势在于,可以显著减少客户端、服务端的来回网络 IO 次数。
所以我给你的建议是:
- String / Hash 使用 MGET/MSET 替代 GET/SET,HMGET/HMSET 替代 HGET/HSET
- 其它数据类型使用 Pipeline,打包一次性发送多个命令到服务端执行
7) 避免集中过期 key
Redis 清理过期 key 是采用定时 + 懒惰的方式来做的,而且这个过程都是在主线程中执行。
如果你的业务存在大量 key 集中过期的情况,那么 Redis 在清理过期 key 时,也会有阻塞主线程的风险。
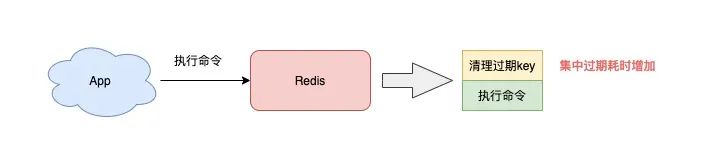
想要避免这种情况发生,你可以在设置过期时间时,增加一个随机时间,把这些 key 的过期时间打散,从而降低集中过期对主线程的影响。
8) 使用长连接操作 Redis,合理配置连接池
你的业务应该使用长连接操作 Redis,避免短连接。
当使用短连接操作 Redis 时,每次都需要经过 TCP 三次握手、四次挥手,这个过程也会增加操作耗时。
同时,你的客户端应该使用连接池的方式访问 Redis,并设置合理的参数,长时间不操作 Redis 时,需及时释放连接资源。
9) 只使用 db0
尽管 Redis 提供了 16 个 db,但我只建议你使用 db0。
为什么呢?我总结了以下 3 点原因:
- 在一个连接上操作多个 db 数据时,每次都需要先执行 SELECT,这会给 Redis 带来额外的压力
- 使用多个 db 的目的是,按不同业务线存储数据,那为何不拆分多个实例存储呢?拆分多个实例部署,多个业务线不会互相影响,还能提高 Redis 的访问性能
- Redis Cluster 只支持 db0,如果后期你想要迁移到 Redis Cluster,迁移成本高
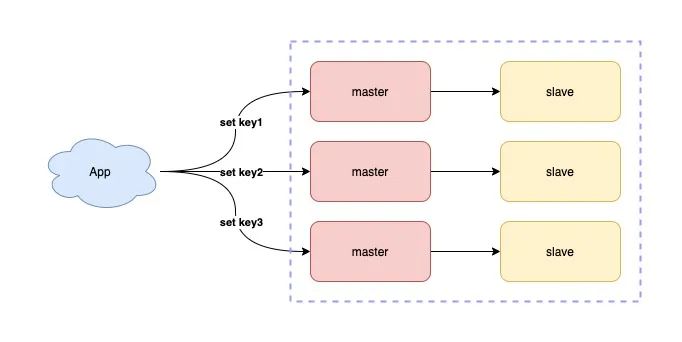
10) 使用读写分离 + 分片集群
如果你的业务读请求量很大,那么可以采用部署多个从库的方式,实现读写分离,让 Redis 的从库分担读压力,进而提升性能。

如果你的业务写请求量很大,单个 Redis 实例已无法支撑这么大的写流量,那么此时你需要使用分片集群,分担写压力。
11) 不开启 AOF 或 AOF 配置为每秒刷盘
如果对于丢失数据不敏感的业务,我建议你不开启 AOF,避免 AOF 写磁盘拖慢 Redis 的性能。
如果确实需要开启 AOF,那么我建议你配置为 appendfsync everysec,把数据持久化的刷盘操作,放到后台线程中去执行,尽量降低 Redis 写磁盘对性能的影响。
12) 使用物理机部署 Redis
Redis 在做数据持久化时,采用创建子进程的方式进行。
而创建子进程会调用操作系统的 fork 系统调用,这个系统调用的执行耗时,与系统环境有关。
虚拟机环境执行 fork 的耗时,要比物理机慢得多,所以你的 Redis 应该尽可能部署在物理机上。
13) 关闭操作系统内存大页机制
Linux 操作系统提供了内存大页机制,其特点在于,每次应用程序向操作系统申请内存时,申请单位由之前的 4KB 变为了 2MB。
这会导致什么问题呢?
当 Redis 在做数据持久化时,会先 fork 一个子进程,此时主进程和子进程共享相同的内存地址空间。
当主进程需要修改现有数据时,会采用写时复制(Copy On Write)的方式进行操作,在这个过程中,需要重新申请内存。
如果申请内存单位变为了 2MB,那么势必会增加内存申请的耗时,如果此时主进程有大量写操作,需要修改原有的数据,那么在此期间,操作延迟就会变大。
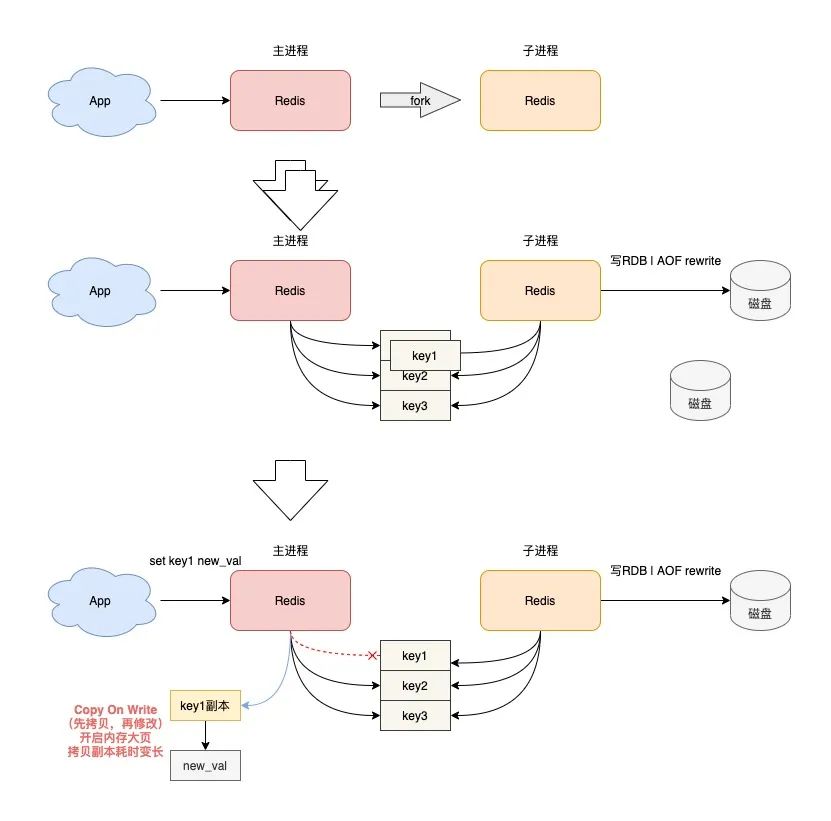
所以,为了避免出现这种问题,你需要在操作系统上关闭内存大页机制。
好了,以上这些就是 Redis 「高性能」方面的实践优化。如果你非常关心 Redis 的性能问题,可以结合这些方面针对性优化。
我们再来看 Redis 「可靠性」如何保证。
03
如何保证 Redis 的可靠性?
这里我想提醒你的是,保证 Redis 可靠性其实并不难,但难的是如何做到「持续稳定」。
下面我会从「资源隔离」、「多副本」、「故障恢复」这三大维度,带你分析保障 Redis 可靠性的最佳实践。
1) 按业务线部署实例
提升可靠性的第一步,就是「资源隔离」。
你最好按不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
这种资源隔离的方案,实施成本是最低的,但成效却是非常大的。
2) 部署主从集群
如果你只使用单机版 Redis,那么就会存在机器宕机服务不可用的风险。
所以,你需要部署「多副本」实例,即主从集群,这样当主库宕机后,依旧有从库可以使用,避免了数据丢失的风险,也降低了服务不可用的时间。
在部署主从集群时,你还需要注意,主从库需要分布在不同机器上,避免交叉部署。
这么做的原因在于,通常情况下,Redis 的主库会承担所有的读写流量,所以我们一定要优先保证主库的稳定性,即使从库机器异常,也不要对主库造成影响。
而且,有时我们需要对 Redis 做日常维护,例如数据定时备份等操作,这时你就可以只在从库上进行,这只会消耗从库机器的资源,也避免了对主库的影响。
3) 合理配置主从复制参数
在部署主从集群时,如果参数配置不合理,也有可能导致主从复制发生问题:
- 主从复制中断
- 从库发起全量复制,主库性能受到影响
在这方面我给你的建议有以下 2 点:
- 设置合理的 repl-backlog 参数:过小的 repl-backlog 在写流量比较大的场景下,主从复制中断会引发全量复制数据的风险
- 设置合理的 slave client-output-buffer-limit:当从库复制发生问题时,过小的 buffer 会导致从库缓冲区溢出,从而导致复制中断
4) 部署哨兵集群,实现故障自动切换
只部署了主从节点,但故障发生时是无法自动切换的,所以,你还需要部署哨兵集群,实现故障的「自动切换」。
而且,多个哨兵节点需要分布在不同机器上,实例为奇数个,防止哨兵选举失败,影响切换时间。
以上这些就是保障 Redis「高可靠」实践优化,你应该也发现了,这些都是部署和运维层的优化。
除此之外,你可能还会对 Redis 做一些「日常运维」工作,这时你要注意哪些问题呢?
04
日常运维 Redis 需要注意什么?
如果你是 DBA 运维人员,在平时运维 Redis 时,也需要注意以下 6 个方面。
1) 禁止使用 KEYS/FLUSHALL/FLUSHDB 命令
执行这些命令,会长时间阻塞 Redis 主线程,危害极大,所以你必须禁止使用它。
如果确实想使用这些命令,我给你的建议是:
- SCAN 替换 KEYS
- 4.0+版本可使用 FLUSHALL/FLUSHDB ASYNC,清空数据的操作放在后台线程执行
2) 扫描线上实例时,设置休眠时间
不管你是使用 SCAN 扫描线上实例,还是对实例做 bigkey 统计分析,我建议你在扫描时一定记得设置休眠时间。
防止在扫描过程中,实例 OPS 过高对 Redis 产生性能抖动。
3) 慎用 MONITOR 命令
有时在排查 Redis 问题时,你会使用 MONITOR 查看 Redis 正在执行的命令。
但如果你的 Redis OPS 比较高,那么在执行 MONITOR 会导致 Redis 输出缓冲区的内存持续增长,这会严重消耗 Redis 的内存资源,甚至会导致实例内存超过 maxmemory,引发数据淘汰,这种情况你需要格外注意。
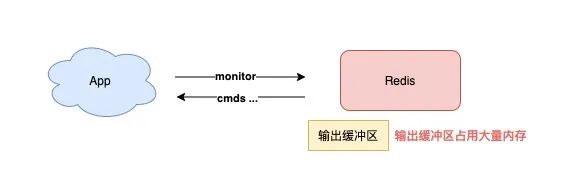
所以你在执行 MONITOR 命令时,一定要谨慎,尽量少用。
4) 从库必须设置为 slave-read-only
你的从库必须设置为 slave-read-only 状态,避免从库写入数据,导致主从数据不一致。
除此之外,从库如果是非 read-only 状态,如果你使用的是 4.0 以下的 Redis,它存在这样的 Bug:
从库写入了有过期时间的数据,不会做定时清理和释放内存。
这会造成从库的内存泄露!这个问题直到 4.0 版本才修复,你在配置从库时需要格外注意。
5) 合理配置 timeout 和 tcp-keepalive 参数
如果因为网络原因,导致你的大量客户端连接与 Redis 意外中断,恰好你的 Redis 配置的 maxclients 参数比较小,此时有可能导致客户端无法与服务端建立新的连接(服务端认为超过了 maxclients)。
造成这个问题原因在于,客户端与服务端每建立一个连接,Redis 都会给这个客户端分配了一个 client fd。
当客户端与服务端网络发生问题时,服务端并不会立即释放这个 client fd。
什么时候释放呢?
Redis 内部有一个定时任务,会定时检测所有 client 的空闲时间是否超过配置的 timeout 值。
如果 Redis 没有开启 tcp-keepalive 的话,服务端直到配置的 timeout 时间后,才会清理释放这个 client fd。
在没有清理之前,如果还有大量新连接进来,就有可能导致 Redis 服务端内部持有的 client fd 超过了 maxclients,这时新连接就会被拒绝。
针对这种情况,我给你的优化建议是:
- 不要配置过高的 timeout:让服务端尽快把无效的 client fd 清理掉
- Redis 开启 tcp-keepalive:这样服务端会定时给客户端发送 TCP 心跳包,检测连接连通性,当网络异常时,可以尽快清理僵尸 client fd
6) 调整 maxmemory 时,注意主从库的调整顺序
Redis 5.0 以下版本存在这样一个问题:从库内存如果超过了 maxmemory,也会触发数据淘汰。
在某些场景下,从库是可能优先主库达到 maxmemory 的(例如在从库执行 MONITOR 命令,输出缓冲区占用大量内存),那么此时从库开始淘汰数据,主从库就会产生不一致。
要想避免此问题,在调整 maxmemory 时,一定要注意主从库的修改顺序:
- 调大 maxmemory:先修改从库,再修改主库
- 调小 maxmemory:先修改主库,再修改从库
直到 Redis 5.0,Redis 才增加了一个配置 replica-ignore-maxmemory,默认从库超过 maxmemory 不会淘汰数据,才解决了此问题。
好了,以上这些就是「日常运维」Redis 需要注意的,你可以对各个配置项查漏补缺,看有哪些是需要优化的。
接下来,我们来看一下,保障 Redis「安全」都需要注意哪些问题。
05
Redis 安全如何保证?
无论如何,在互联网时代,安全问题一定是我们需要随时警戒的。
你可能听说过 Redis 被注入可执行脚本,然后拿到机器 root 权限的安全问题,都是因为在部署 Redis 时,没有把安全风险注意起来。
针对这方面,我给你的建议是:
- 不要把 Redis 部署在公网可访问的服务器上
- 部署时不使用默认端口 6379
- 以普通用户启动 Redis 进程,禁止 root 用户启动
- 限制 Redis 配置文件的目录访问权限
- 推荐开启密码认证
- 禁用/重命名危险命令(KEYS/FLUSHALL/FLUSHDB/CONFIG/EVAL)
只要你把这些做到位,基本上就可以保证 Redis 的安全风险在可控范围内。
至此,我们分析了 Redis 在内存、性能、可靠性、日常运维方面的最佳实践优化。
除了以上这些,你还需要做到提前「预防」。
06
如何预防 Redis 问题?
要想提前预防 Redis 问题,你需要做好以下两个方面:
- 合理的资源规划
- 完善的监控预警
先来说资源规划。
在部署 Redis 时,如果你可以提前做好资源规划,可以避免很多因为资源不足产生的问题。这方面我给你的建议有以下 3 点:
- 保证机器有足够的 CPU、内存、带宽、磁盘资源
- 提前做好容量规划,主库机器预留一半内存资源,防止主从机器网络故障,引发大面积全量同步,导致主库机器内存不足的问题
- 单个实例内存建议控制在 10G 以下,大实例在主从全量同步、RDB 备份时有阻塞风险
再来看监控如何做。
监控预警是提高稳定性的重要环节,完善的监控预警,可以把问题提前暴露出来,这样我们才可以快速反应,把问题最小化。
这方面我给你的建议是:
- 做好机器 CPU、内存、带宽、磁盘监控,资源不足时及时报警,任意资源不足都会影响 Redis 性能
- 设置合理的 slowlog 阈值,并对其进行监控,slowlog 过多及时报警
- 监控组件采集 Redis INFO 信息时,采用长连接,避免频繁的短连接
- 做好实例运行时监控,重点关注 expired_keys、evicted_keys、latest_fork_usec 指标,这些指标短时突增可能会有阻塞风险
相关文章:
Redis是什么? 日常运维 Redis 需要注意什么 ? 怎么降低Redis 内存使用 节省内存?
你的项目或许已经使用 Redis 很长时间了,但在使用过程中,你可能还会或多或少地遇到以下问题: 我的 Redis 内存为什么增长这么快?为什么我的 Redis 操作延迟变大了?如何降低 Redis 故障发生的频率?日常运维…...
【Android项目】“追茶到底”项目介绍
没有多的介绍,这里只是展示我的项目效果,后面会给出具体的代码实现。 一、用户模块 1、注册(第一次登陆的话需要先注册账号) 2、登陆(具有记住最近登录用户功能) 二、点单模块 1、展示饮品列表 2、双向联动…...
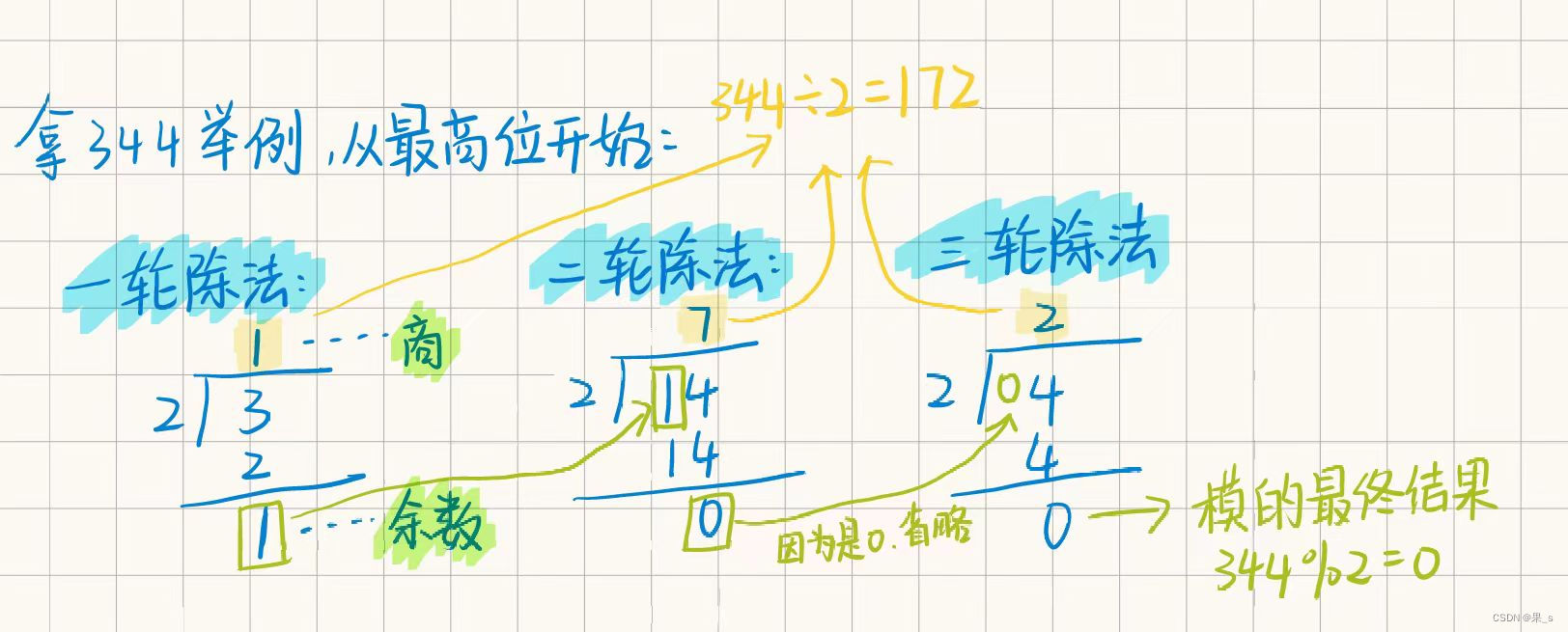
机试:进制转换问题
十进制转任意进制 简单回忆一下十进制我们是怎么转换成二进制的(短除法): 我们会将十进制数不断的进行除2操作,并且记录下每一次的余数(这个余数就是我们最终求的二进制数的组成部分)。 以下以12D举例&a…...

目标检测实战(十五): 使用YOLOv7完成对图像的目标检测任务(从数据准备到训练测试部署的完整流程)
文章目录 一、目标检测介绍二、YOLOv7介绍三、源码/论文获取四、环境搭建4.1 环境检测 五、数据集准备六、 模型训练七、模型验证八、模型测试九、错误总结9.1 错误1-numpy jas mp attribute int9.2 错误2-测试代码未能跑出检测框9.3 错误3- Command git tag returned non-zero…...

github中fasttext库README官文文档翻译
参考链接:fastText/python/README.md at main facebookresearch/fastText (github.com) fastText模块介绍 fastText 是一个用于高效学习单词表述和句子分类的库。在本文档中,我们将介绍如何在 python 中使用 fastText。 环境要求 fastText 可在现代 …...
WouoUIPagePC端实现
WouoUIPagePC端实现 WouoUIPage是一个与硬件平台无关,纯C语言的UI库(目前只能应用于128*64的单色OLED屏幕上,后期会改进,支持更多尺寸)。因此,我们可以在PC上实现它,本文就以在PC上使用 VScode…...

W801学习笔记十九:古诗学习应用——下
经过前两章的内容,背唐诗的功能基本可以使用了。然而,仅有一种模式未免显得过于单一。因此,在本章中对其进行扩展,增加几种不同的玩法,并且这几种玩法将采用完全不同的判断方式。 玩法一:三分钟限时挑战—…...
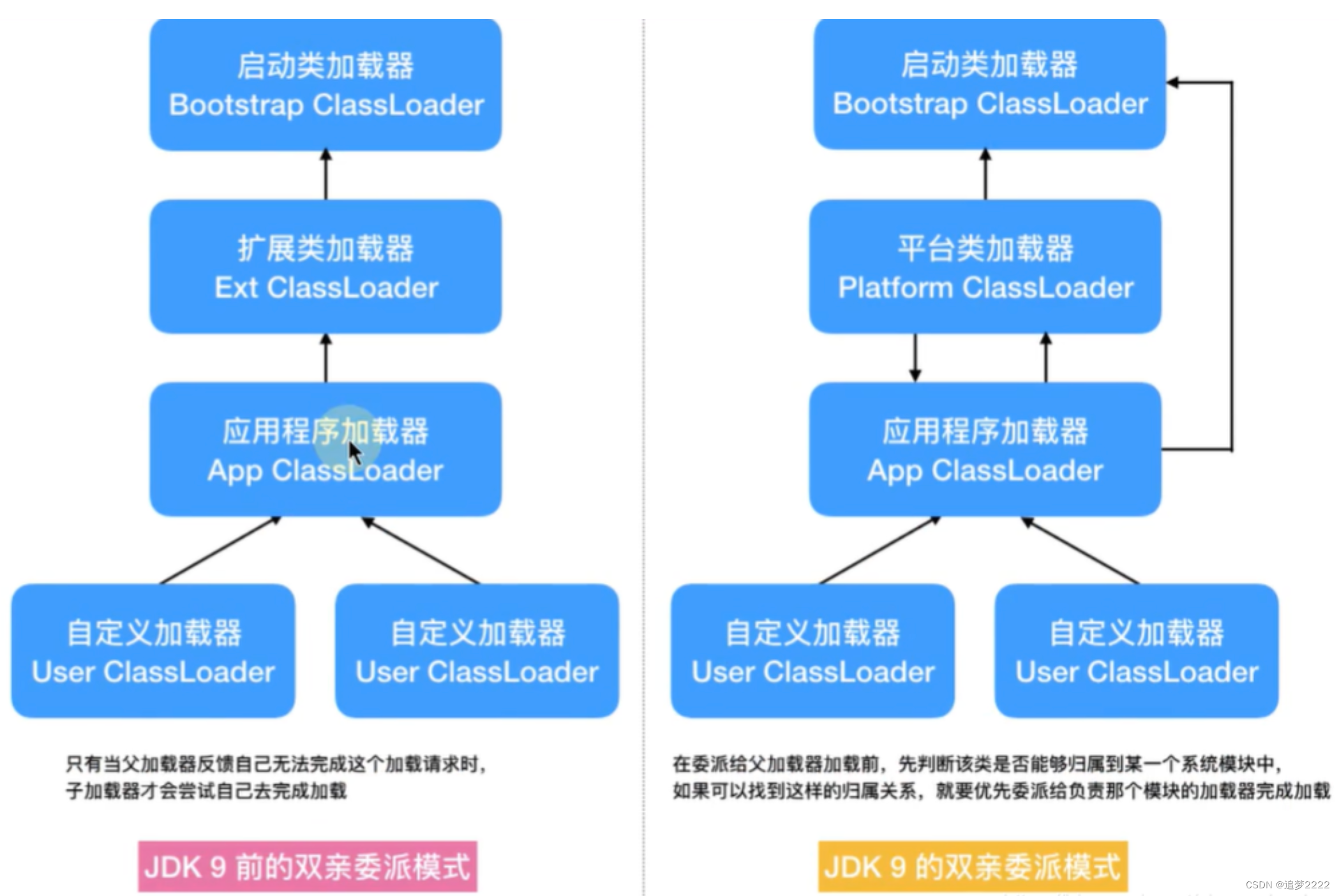
类加载器ClassLoad-jdk1.8
类加载器ClassLoad-jdk1.8 1. 类加载器的作用2. 类加载器的种类(JDK8)3. jvm内置类加载器如何搜索加载类--双亲委派模型4. 如何打破双亲委派模型--自定义类加载器5. 自定义一个类加载器5.1 为什么需要自定义类加载器5.2 自定义一个类加载器 6. java代码加…...
24年最新AI数字人简单混剪
24年最新AI数字人简单混剪 网盘自动获取 链接:https://pan.baidu.com/s/1lpzKPim76qettahxvxtjaQ?pwd0b8x 提取码:0b8x...

免备案香港主机会影响网站收录?
免备案香港主机会影响网站收录?前几天遇到一个做电子商务的朋友说到这个使用免备案香港主机的完整会不会影响网站的收录问题,这个问题也是站长关注较多的问题之一。小编查阅了百度官方规则说明,应该属于比较全面的。下面小编给大家介绍一下使用免备案香…...

低代码工业组态数字孪生平台
2024 两会热词「新质生产力」凭借其主要特征——高科技、高效能及高质量,引发各界关注。在探索构建新质生产力的重要议题中,数据要素被视为土地、劳动力、资本和技术之后的第五大生产要素。数据要素赋能新质生产力发展主要体现为:生产力由生产…...
代码随想录第三十八天(完全背包问题)|爬楼梯(第八期模拟笔试)|零钱兑换|完全平方数
爬楼梯(第八期模拟笔试) 该题也是昨天的完全背包排列问题,解法相同,将遍历顺序进行调换 import java.util.*; public class Main{public static void main (String[] args) {Scanner scnew Scanner(System.in);int nsc.nextInt(…...

idea常用知识点随记
idea常用知识点随记 1. 打开idea隐藏的commit窗口2. idea中拉取Git分支代码3. idea提示代码报错,项目编译没有报错4. idea中实体类自动生成序列号5. idea隐藏当前分支未commit代码6. idea拉取新建分支的方法 1. 打开idea隐藏的commit窗口 idea左上角File→Settings…...
(双指针) 有效三角形的个数 和为s的两个数字 三数之和 四数之和
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 文章目录 前言 一、有效三角形的个数(medium) 1.1、题目 1.2、讲解算法原理 1.3、编写代码 二、和为s的两个数字 2.1、题目 2.2、讲解算…...
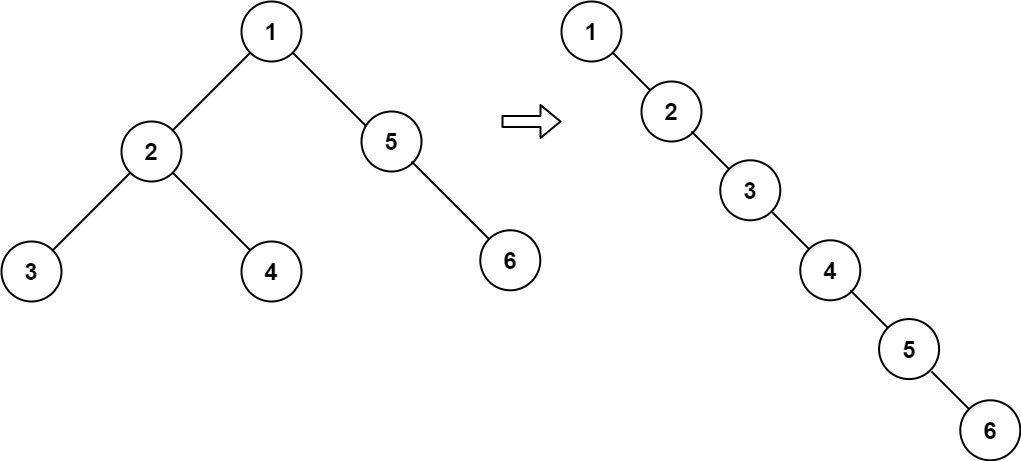
力扣每日一题114:二叉树展开为链表
题目 中等 提示 给你二叉树的根结点 root ,请你将它展开为一个单链表: 展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。展开后的单链表应该与二叉树 先序遍历 顺序相同…...
Linux系统下使用LVM扩展逻辑卷的步骤指南
Linux系统下使用LVM扩展逻辑卷的步骤指南 文章目录 Linux系统下使用LVM扩展逻辑卷的步骤指南前言一、逻辑卷管理(LVM)简介二、扩展逻辑卷步骤1. 检查当前的磁盘布局2. 创建新的分区3. 更新内核的分区表4. 初始化新的物理卷5. 将物理卷添加到卷组6. 调整逻…...
探索AI编程新纪元:从零开始的智能编程之旅
提示:Baidu Comate 智能编码助手是基于文心大模型,打造的新一代编码辅助工具 文章目录 前言AI编程概述:未来已来场景需求:从简单到复杂,无所不包体验步骤:我的AI编程初探试用感受:双刃剑下的深思…...

RustGUI学习(iced)之小部件(三):如何使用下拉列表pick_list?
前言 本专栏是学习Rust的GUI库iced的合集,将介绍iced涉及的各个小部件分别介绍,最后会汇总为一个总的程序。 iced是RustGUI中比较强大的一个,目前处于发展中(即版本可能会改变),本专栏基于版本0.12.1. 概述 这是本专栏的第三篇,主要讲述下拉列表pick_list部件的使用,会…...
【OceanBase诊断调优】—— Unit 迁移问题的排查方法
适用版本:V2.1.x、V2.2.x、V3.1.x、V3.2.x 本文主要介绍 OceanBase 数据集在副本迁移过程中遇到的问题的排查方法。 适用版本 V2.1.x、V2.2.x、V3.1.x、V3.2.x 手动调度迁移问题的排查 OceanBase 数据库的 RootService 模块负责 Unit 迁移的调度,如果…...
[极客大挑战 2019]PHP
1.通过目录扫描找到它的备份文件,这里的备份文件是它的源码。 2.源码当中涉及到的关键点就是魔术函数以及序列化与反序列化。 我们提交的select参数会被进行反序列化,我们要构造符合输出flag条件的序列化数据。 但是,这里要注意的就是我们提…...
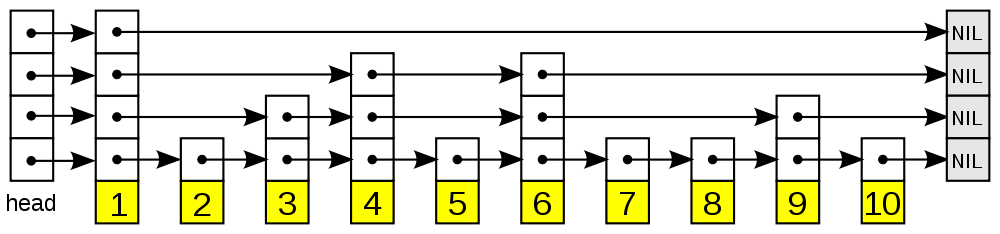
数据结构之跳跃表
跳跃表 跳跃表(skiplist)是一种随机化的数据, 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— …...
搜维尔科技:动作捕捉解决方案:销售、服务、培训和支持
动作捕捉解决方案:销售、服务、培训和支持 搜维尔科技:动作捕捉解决方案:销售、服务、培训和支持l...
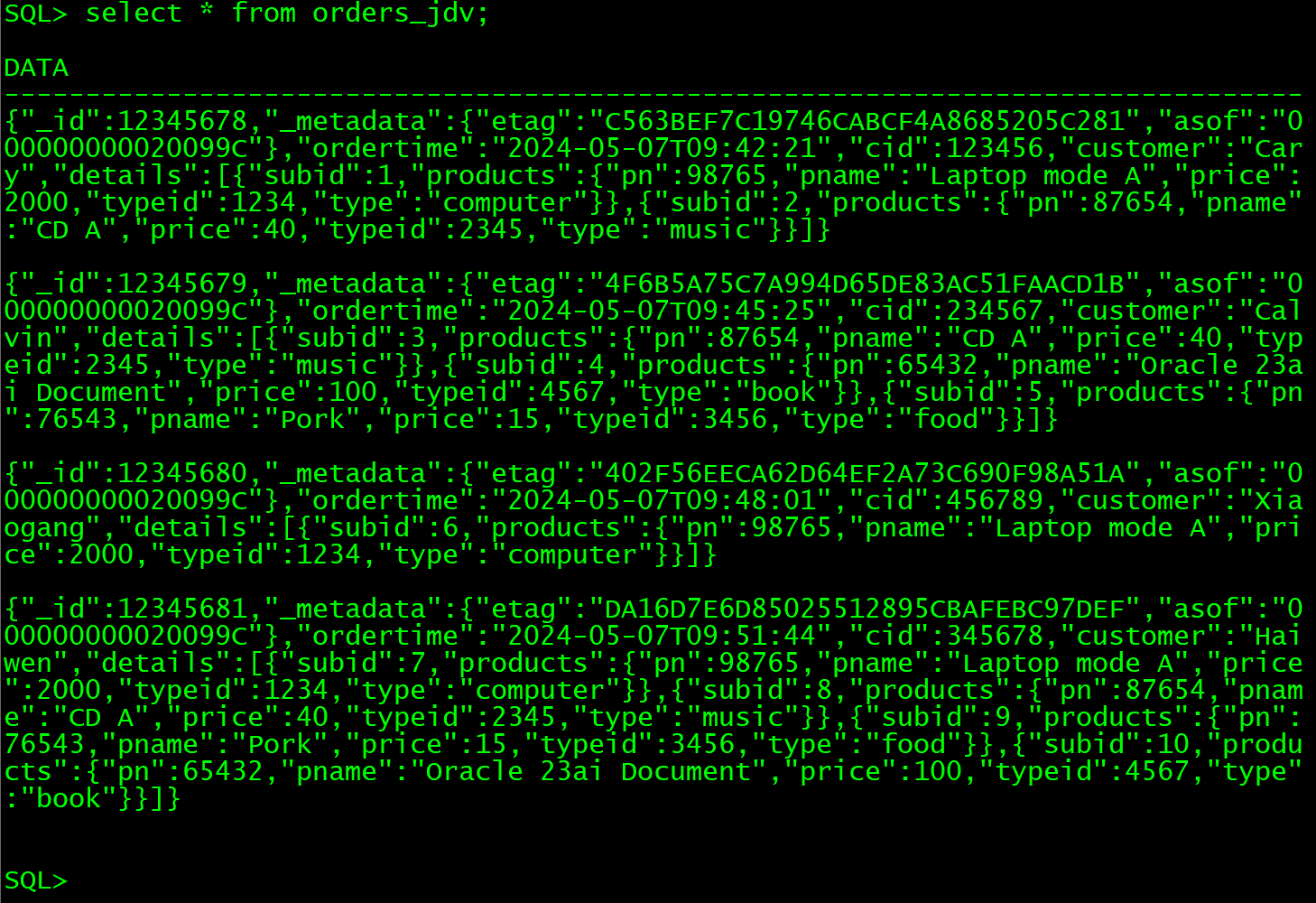
数据库管理-第184期 23ai:干掉MongoDB的不一定是另一个JSON数据库(20240507)
数据库管理184期 2024-05-07 数据库管理-第184期 23ai:干掉MongoDB的不一定是另一个JSON数据库(20240507)1 JSON需求2 关系型表设计3 JSON关系型二元性视图3 查询视图总结 数据库管理-第184期 23ai:干掉MongoDB的不一定是另一个JSON数据库(20…...
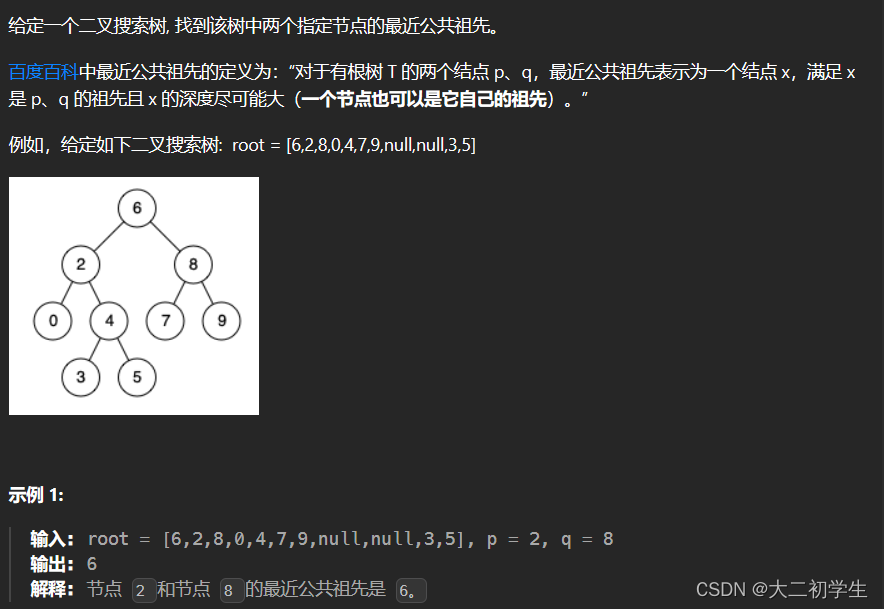
刷代码随想录有感(58):二叉树的最近公共祖先
题干: 代码: class Solution { public:TreeNode* traversal(TreeNode* root, TreeNode* p, TreeNode* q){if(root NULL)return NULL;if(root p || root q)return root;TreeNode* left traversal(root->left, p, q);TreeNode* right traversal(r…...
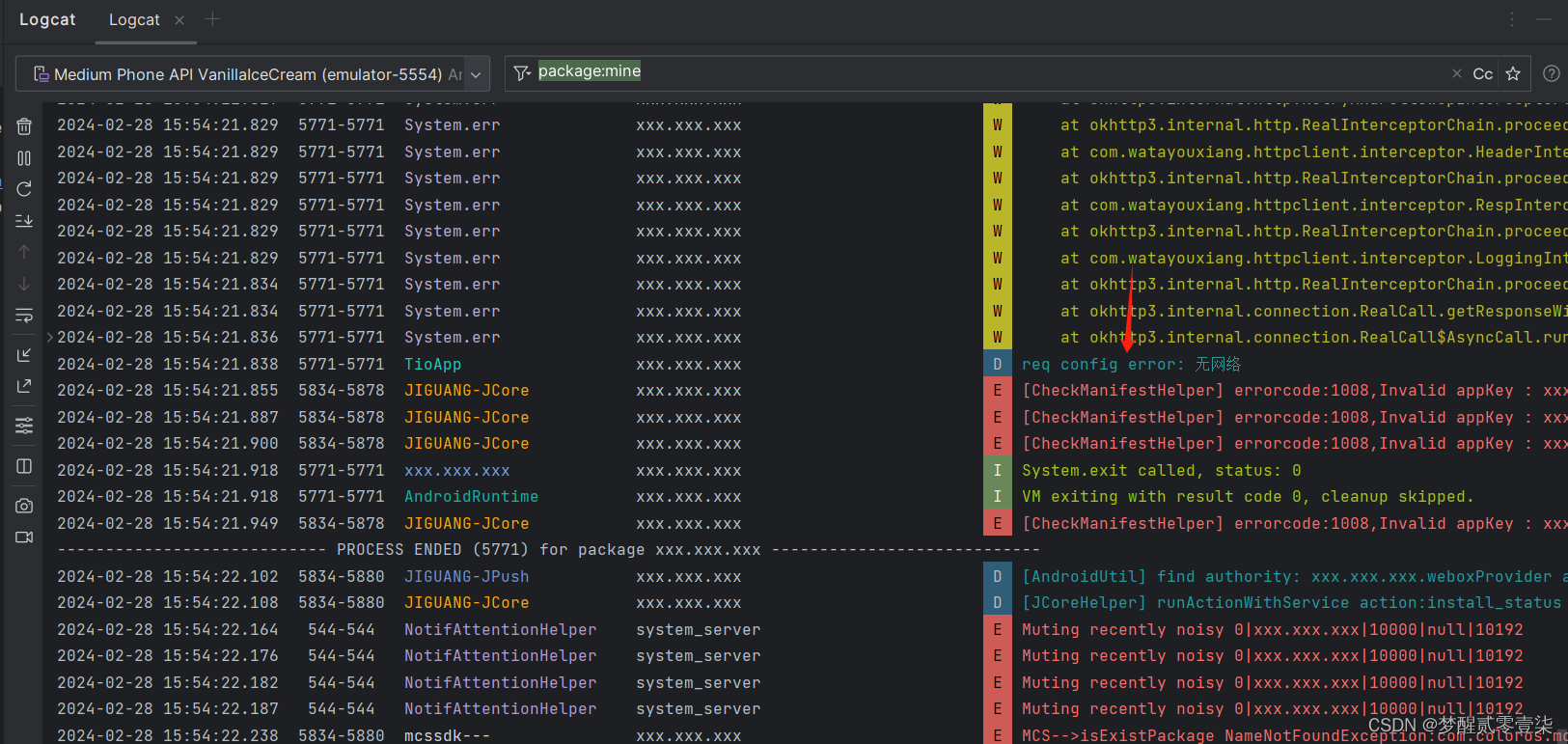
[开发|安卓] Android Studio 开发环境配置
Android Studio下载 Android Studio下载地址 下载SDK依赖 1.点击左上角菜单 2.选择工具 3.打开SDK管理中心 4.下载项目目标Android版本的SDK 配置安卓虚拟机 1.打开右上角的设备管理 2.选择合适的手机规格 3.下载并选择项目目标Android系统 4.点击完成配置 …...
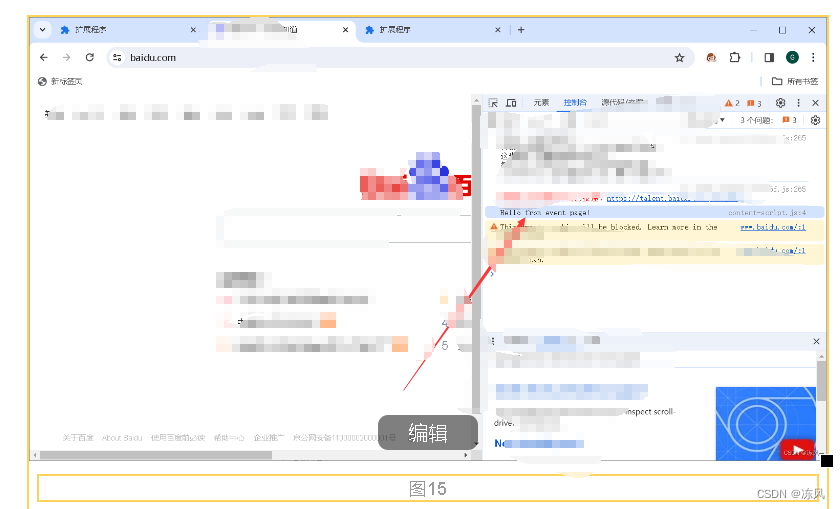
开发 Chrome 浏览器插件入门
目录 前言 一,创建插件 1.创建一个新的目录 2.编写清单文件 二,高级清单文件 1.编写放置右窗口 2.常驻的后台JS或后台页面 3.event-pages 短周期使用 三,Chrome 扩展 API 函数 1.浏览器操作函数 2.内容脚本函数 3.后台脚本函数 4…...
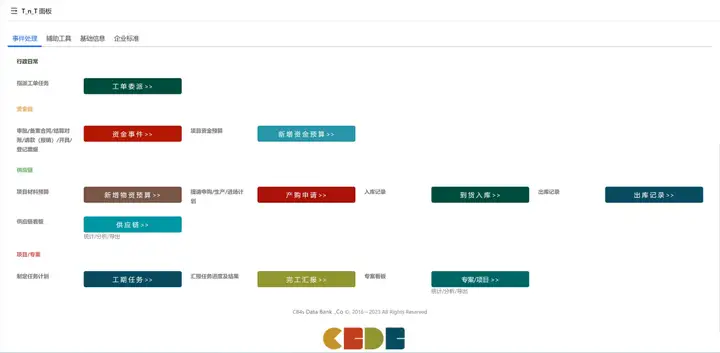
在数字化转型的浪潮中,CBDB百数服务商如何破浪前行?
在信息化时代,传统咨询企业面临着数字化转型的挑战与机遇。如何利用数字化技术提升业务效率、增强客户黏性,成为了行业关注的焦点。云南析比迪彼企业管理有限公司(CBDB)作为云南地区的企业咨询服务提供商,率先与百数展…...

程序员的实用神器
在软件开发的海洋中,程序员的实用神器如同航海中的指南针,帮助他们导航、加速开发、优化代码质量,并最终抵达成功的彼岸。这些工具覆盖了从代码编写、版本控制到测试和部署的各个环节。然而,程序员们通常会有一套自己喜欢的工具集…...
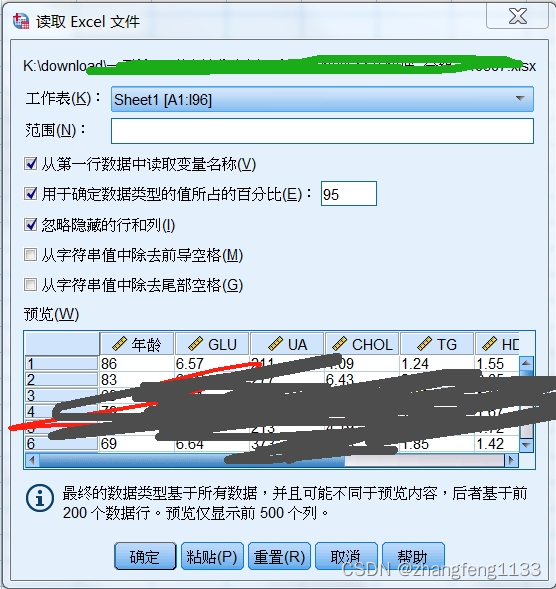
spss 导入数据的时候 用于确定数据类型的值所在的百分比95%是什么意思,数据分析,医学数据分析
在SPSS中,当提及“数据类型的值所在的百分比95%”时,这通常与数据的统计分布或置信区间有关,而不是直接关于数据类型的定义。 导入数据的时候需要定义数据类型,那么根据提供的数据,来定义,有时候ÿ…...
Python进阶之-上下文管理器
✨前言: 🌟什么是上下文管理器? 在Python中,上下文管理器是支持with语句的对象,用于为代码块提供设置及清理代码。上下文管理器广泛应用于资源管理场景,例如文件操作、网络连接、数据库会话等,…...

什么年代了,还在拿考勤说事
最近,看到了某公司的一项考勤规定:自然月内,事假累计超过3次或者累计请假时间超过8小时的,不予审批,强制休假的按旷工处理。 真的想吐槽,什么年代了,还在拿考勤说事,这是什么公司、什…...

泰迪智能科技中职大数据实验室建设(职业院校大数据实验室建设指南)
职校大数据实验室是职校校园文化建设的重要部分,大数据实训室的建设方案应涵盖多个方面,包括硬件设施的配备、软件环境的搭建、课程资源的开发、师资力量的培养以及实践教学体系的完善等。 打造特色,对接生产 社会经济与产业的…...
Qt QThreadPool线程池
1.简介 QThreadPool类管理一个QThread集合。 QThreadPool管理和重新设计单个QThread对象,以帮助降低使用线程的程序中的线程创建成本。每个Qt应用程序都有一个全局QThreadPool对象,可以通过调用globalInstance来访问该对象。 要使用其中一个QThreadPool…...

无人机+三维建模:倾斜摄影技术详解
无人机倾斜摄影测量技术是一项高新技术,近年来在国际摄影测量领域得到了快速发展。这种技术通过从一个垂直和四个倾斜的五个不同视角同步采集影像,从而获取到丰富的建筑物顶面及侧视的高分辨率纹理。这种技术不仅能够真实地反映地物情况,还能…...
Window(Qt/Vs)软件添加版本信息
Window(Qt/Vs)软件添加版本信息 文章目录 Window(Qt/Vs)软件添加版本信息VS添加版本信息添加资源文件添加版本定义头自动更新版本添加批处理脚本设置生成事件 Qt添加版本信息添加资源文件文件信息修改自动更新版本 CMake添加版本信…...

工厂模式+策略模式完成多种登录模式的实现
前提 (简单工厂不属于设计模式,而是一种编程思想【抽象一层出来】)工厂方法模式、抽象工厂模式 以上都是为了解耦,如果考虑多个纬度(如需要同时考虑多种电器,多种品牌)则优先考虑抽象工厂。 …...

赋能企业数字化转型 - 易点易动固定资产系统与飞书实现协同管理
在当前瞬息万变的商业环境下,企业如何借助信息化手段提升管理效率,已经成为摆在各行各业面前的紧迫课题。作为企业数字化转型的重要一环,固定资产管理的信息化建设更是不容忽视。 易点易动作为国内领先的企业资产管理服务商,凭借其全方位的固定资产管理解决方案,助力众多企业实…...
Sectigo 通配符SSL证书的优势分析!
Sectigo 通配符证书是一种专为需要保护同一主域名下的多个子域名而设计的安全解决方案。以下是Sectigo通配符证书的主要优势和特点: 1. 域名灵活性:使用通配符(*)符号,一张Sectigo通配符证书即可覆盖一个主域名及其所有…...
nuxt2路由,以及重构以前项目,路由使用
Nuxt.js根据pages目录结构自动生成vue-router模块的路由配置。 配置生成的路由可在.nuxt文件下的router.js文件中查看到,如: export const routerOptions {mode: history,base: /,linkActiveClass: nuxt-link-active,linkExactActiveClass: nuxt-link…...
eureka报错:链接8761被拒绝
eureka报错:链接8761被拒绝 来龙去脉 在idea环境中运行没有问题 我的配置是: server: port: 8001 spring: application: name: registry-server eureka: instance: hostname: localhost client: fetch-registry: false register-with-eureka: false …...

Linux 手动部署JDK21 环境
1、下载包(我下载的是tar) https://www.oracle.com/cn/java/technologies/downloads/#java21 完成后进行上传 2、检查已有JDK,并删除(我原有是jdk8) rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps3、清理掉 profile中的j…...
【c2】编译预处理,gdb,makefile,文件,多线程,动静态库
文章目录 1.编译预处理:C源程序 - 编译预处理【#开头指令和特殊符号进行处理,删除程序中注释和多余空白行】- 编译2.gdb调试:多进/线程中无法用3.makefile文件:make是一个解释makefile中指令的命令工具4.文件:fprint/f…...
c++结构体用构造函数进行初始化
结构体能自由组装数据,是一种很常见的数据打包方法。 当我们定义一个结构体后,没有初始化就使用,就会使用到垃圾数据,而且这种错误很难发现。 在编程时对于定义的任何变量,我们最好都先初始化。 常见的操作是每定义…...
2024年五一数学建模C题完整解题思路代码
2024年第二十一届五一数学建模竞赛题目 C题 煤矿深部开采冲击地压危险预测 煤炭是中国的主要能源和重要的工业原料。然而,随着开采深度的增加,地应力增大,井下煤岩动力灾害风险越来越大,严重影响着煤矿的安全高效开采。在各类深…...
0018__GTK+:GTK+的简介、安装、使用方法之详细攻略
GTK:GTK的简介、安装、使用方法之详细攻略-CSDN博客...

环保访谈|浙江双视专注红外机器视觉及智能化应用,保障安全生产
近期,中联环保圈希姐采访了浙江双视科技股份有限公司环保行业销售总监孙波,深入了解了双视科技的发展历程、产品和解决方案、合作流程、核心竞争力以及未来规划。 双视于2014年创立,专注于红外机器视觉、人工智能技术与应用开发,…...
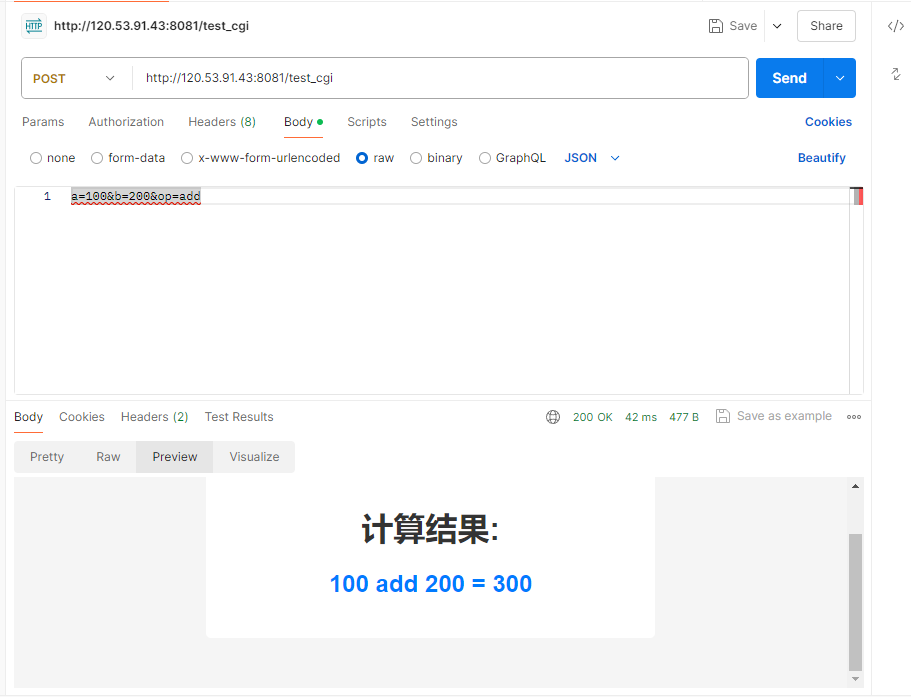
Web服务器
代码: WebServer 介绍 HTTP层 POST请求一般会包含Content-Length字段, 告诉服务器请求主体的长度GET请求一般不会包含Content-Length字段, 它一般不含请求正文POST响应: Content-Type字段, 根据请求资源的后缀填写 编写 1.读取请求与分析请求 2.根据不同请求方法构建不同的响…...
linux的firmware和hal层
linux的firmware和hal层 在Linux中,固件(firmware)和硬件抽象层(Hardware Abstraction Layer,HAL)是两个不同的概念。固件是运行在硬件设备上的程序,它们通常被用来控制硬件的操作。而HAL是一种…...
从ETL与ELT谈起,理解数仓的任务
最近有个朋友,有几十 PB 的异构数据,数据源包括 MySQL、DB2、Oracle、CSV、磁带机,等等,然后他需要把这些数据中的一些信息做关联整合,从这几十 PB 的数据中提取出若干业务字段到数据仓库,做统一分析。 数…...

esp32-cam 2. python opencv 拉取摄像头内容
0. 环境 - win10 python3 - pycharm - esp32-cam http://192.168.4.1 1. 创建工程 File -> Create Project -> -> Location: E:\Workspaces\PycharmProjects\esp32cam_opencv -> Create 2. opencv hello 2.1 添加脚本 File -> New -> Python f…...
【亚马逊云】注册APN账号及报考AWS认证考试说明演示
文章目录 1. 登录AWS网站2. 注册APN账号3. 更改APN账号密码(选)4. 修改APN账号信息(选)5. 查看AWS认证情况(选)6. AWS认证考试报名流程7. 修改报名控制台语言版本(选)8. 开始报名AWS…...
【Golang】 Go语言中如何将参数添加到URL中
文章目录 前言一、参数解释二、代码实现三、总结 前言 在开发Web应用程序时,我们经常需要将参数添加到URL中,以便将数据发送到服务器。这些参数通常用于GET请求,以向服务器传递查询条件或其他信息。在Go语言中,我们可以使用net/u…...

【JavaEE】Servlet
文章目录 一、Servlet 是什么二、如何创建Servlet程序1、创建项目2、引入依赖3、创建目录4、编写代码5、打包程序6、部署程序7、验证程序 一、Servlet 是什么 二、如何创建Servlet程序 1、创建项目 2、引入依赖 Maven 项目创建完后,会自动生成一个 pom.xml 的文…...

幻兽帕鲁Palworld服务器手动+docker部署方法+备份迁移
目录 帕鲁部署官方文档帕鲁手动安装法手动安装steamcmd通过steamcmd安装帕鲁后端 docker容器一键部署幻兽帕鲁绿联云NAS机器部署幻兽帕鲁客户端连接附录1:PalServer.sh的启动项附录2:配置文件游戏存档保存和迁移 关于阿里云计算巢 帕鲁部署官方文档 htt…...
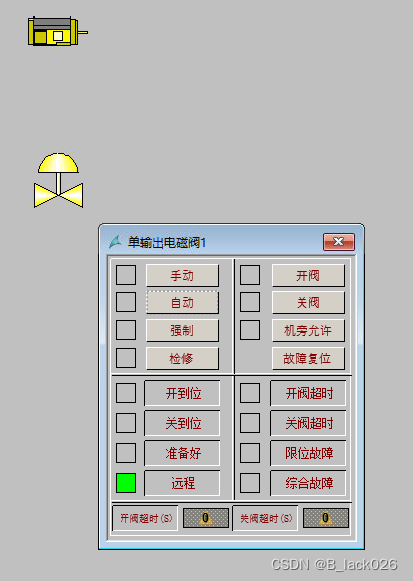
C脚本实现Wincc弹窗重复调用
文章目录 前言一、步骤及解析二、运行画面演示三、总结 前言 在常见的Wincc上位机画面中,点击按钮或控件弹出弹窗,由于不同的弹窗内容不同,变量前缀不同,通常情况下一个弹窗就需要调用一个画面窗口,但画面窗口过多会导…...
C++后端领域聚焦——存储系统和分布式系统
编程语言和脚本 C/C: 作为核心技能,需要深入理解并熟练使用 C/C 进行开发。Shell: 掌握常用的 Shell 脚本,有助于自动化日常任务和环境配置。Python: 常用于脚本编写、自动化测试、数据处理等,提高开发效率。 计算机基础 数据结构和算法: …...